This blog describe one of the many ways to load a csv data file into AWS dynamodb database. This option described here leverages lambda service. AWS lambda is server-less; so no need to setup and configure a server. Further, AWS Lambda gives flexibility to pick language of choice. This blog show a lambda function in python.
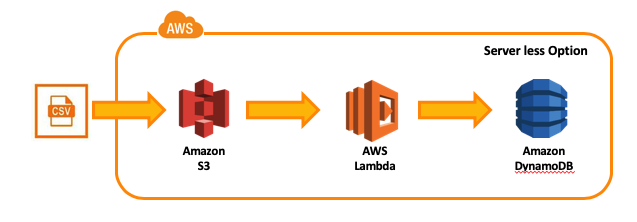
Step 1 : Load csv file into S3
We will load simple csv file containing employee data. The example here demonstrates handling different data types like; string, number and Boolean.
| Field | Type |
|---|---|
| Employee Id | Number |
| Name | String |
| Salary | Double |
| parttime | Boolean |
Sample records (in employee.csv)
1,”Chaks, Raj”,”$300,000”, False
2,”Chen, Joe”,”$250,000”, False
3,”Kumar, Harry”,”$240,000”, True
Drag and drop the file into S3 bucket or use cli command to copy file from local computer to s3. Below is the cli command
$ aws s3 cp employee.csv s3://my-bucket/
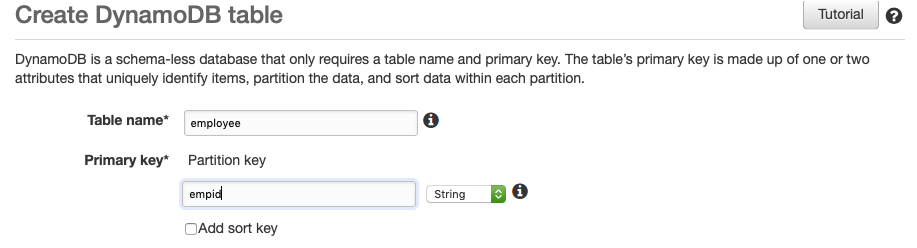
Step 2 : Set up table in DynamoDB
Amazon DynamoDB is a fully-managed NoSQL database service that offers speedy performance and scalability to store and retrieve any amount of data.
Log into aws and create a table in DynamoDB as below
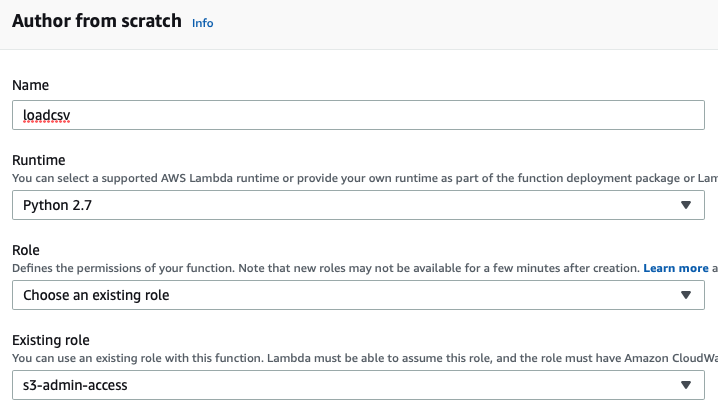
Step 3 Create AWS Lambda function
Goto AWS Lambda and create a new lambda function from scratch as below
On the next screen, before writing the code in the editor, scroll down and make sure that lambda has role that can access s3 bucket and also set the timeout to sufficiently large value so that file can be loaded into dynamodb.
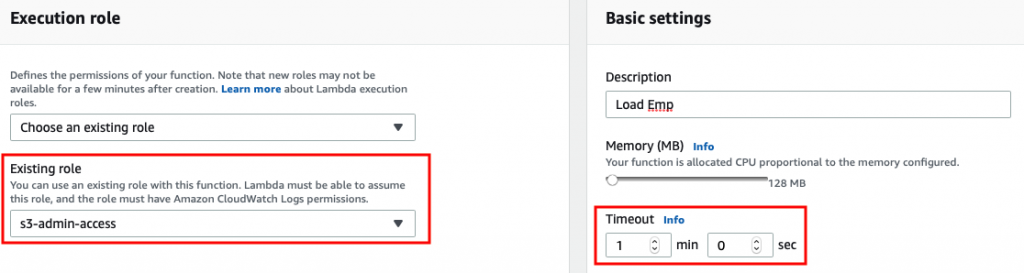
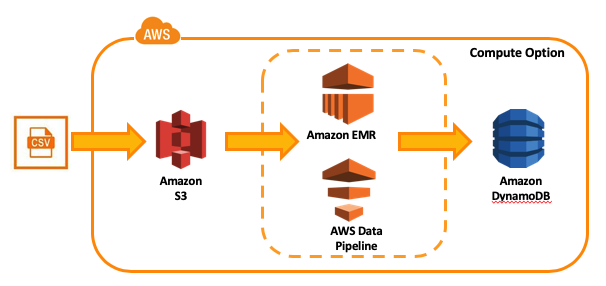
If you anticipate that load time will exceed 15 minutes then you have to resort to non lambda approach to load data, one possible approach is to use data pipeline and EMR services
Step 4 Write AWS Lambda function
The function imports boto3 which is (AWS) SDK for Python. It enables Python code to create, configure, and manage AWS services. It provides an easy to use, object-oriented API, as well as low-level access to AWS services.
The code here uses boto3 and csv, both these are readily available in the lambda environment. All we need to do is write the code that use them to reads the csv file from s3 and loads it into dynamoDB.
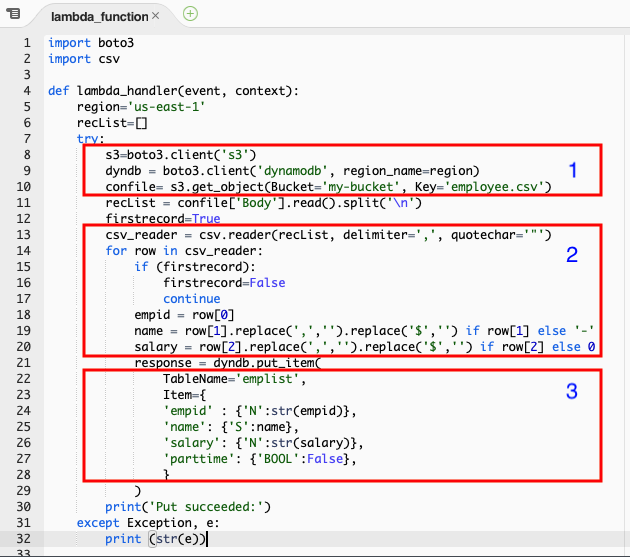
Block 1 : Create the reference to s3 bucket, csv file in the bucket and the dynamoDB.
Block 2 : Loop the reader of csv file using delimiter. DynamoDB may not allow null values hence if else statement assign ‘-‘ for string and 0 for number. It ignores the header row. Notice ‘replace’ removes the comma separator and $ from the amount.
Block 3 : Puts each record in dynamoDB table. ‘N, ‘S’ and ‘BOOL’ indicate the data type of the column in table.
Below is the listing that can be copied into lambda editor
import boto3
import csv
def lambda_handler(event, context):
region='us-east-1'
recList=[]
try:
s3=boto3.client('s3')
dyndb = boto3.client('dynamodb', region_name=region)
confile= s3.get_object(Bucket='my-bucket', Key='employee.csv')
recList = confile['Body'].read().split('\n')
firstrecord=True
csv_reader = csv.reader(recList, delimiter=',', quotechar='"')
for row in csv_reader:
if (firstrecord):
firstrecord=False
continue
empid = row[0]
name = row[1].replace(',','').replace('$','') if row[1] else '-'
salary = row[2].replace(',','').replace('$','') if row[2] else 0
response = dyndb.put_item(
TableName='emplist',
Item={
'empid' : {'N':str(empid)},
'name': {'S':name},
'salary': {'N':str(salary)},
'parttime': {'BOOL':False},
}
)
print('Put succeeded:')
except Exception, e:
print (str(e))